
안녕하세요. 현재 chatGPT의 뛰어난 성능으로 LLM, LangChain, RAG등 여러 요소들이 주목받기 시작했습니다. 사실 RAG는 chatGPT가 주목받기 전부터 자연어처리분야에서 종종 쓰이던 기술이였는데요. RAG는 자연어처리 분야에서도 QA, MRC분야 특히 ODQA분야에서 주목을 받던 기술입니다. RAG의 풀 네임은 Retrieval Augmented Generation인데요. 2020년 NeurlPs에 Accept이 되면서 주목을 받기 시작했습니다. 사실 RAG는 2021년 모 부트캠프에서 MRC에 대한 논문 흐름을 이야기하는 세미나를 했었는데요. MRC흐름을 공부하느라 RAG를 언급하고 공부했던 기억이 나는데, 다시금 2023년에 엄청난 주목을 받으니 새삼 신기하더라구요. RAG의 구조는 다음과 같이 생겼습니다.
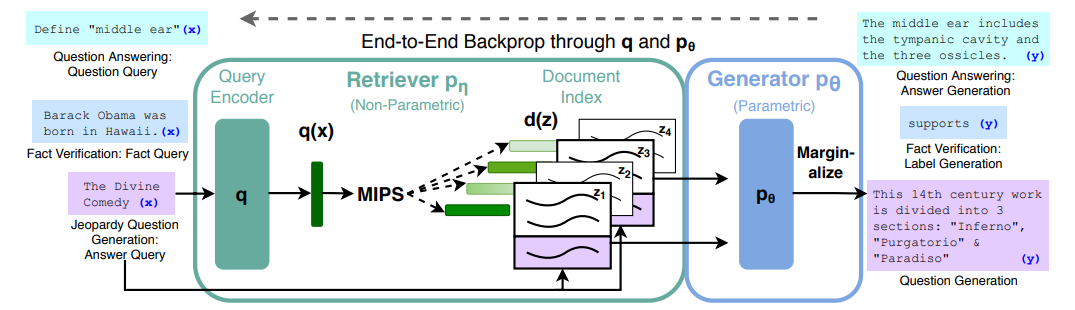
논문에서 소개하고 있는 RAG는 언어 생성을 위해 pre-trained parametric(언어모델)과 non-parametric memory (external knowledge index)를 결합합니다. RAG는 모든 seq2seq task에서 fine-tuned할 수 있고, retriever과 seq2seq task가 함께 학습이 됩니다. 이전 QA는 extractive방식을 사용했는데 RAG는 generation을 사용해 성능이 우수한 것으로 알려져 있습니다.

- Retriever는 입력 시퀀스를 사용하여 DPR retriever로 구현된 텍스트 구절을 검색합니다.
- Generator는 대상 시퀀스를 생성할 때 context와 질문이 단순히 연결되는 추가 context로 사용이 됩니다.
RAG의 retriever + generator는 Negative Log-Likelihood(NLL)손실을 최소화하도록 공동으로 훈련됩니다. 디코딩 혹은 테스트시에 beam search를 통해 RAG 토큰을 평가할 수 있습니다. RAG-seq는 각 후보 문서에 대해 beam search를 실행해 최적의 문서를 선택하게 됩니다.
LangChain라이브러리가 생겨나기 이전에는 이렇게 훈련을 시켜서 결과를 도출했었는데요. LangChain에서 제공하는 라이브러리를 사용하면, 그 어렵던 QA와 MRC분야도 쉽게 구현가능한 시대가 되었습니다.
실질적으로 RAG를 수행하는 부분은 RetrivalQA부분인데, 이 QA를 진행하기 위해서는 VectorStoreDB가 필요하고, 모델 인풋으로 들어가기 위해 Text를 Splitter하는 부분이 필요합니다. LangChain에서 제공하는 TextSplitter도 여러 종류를 제공하는데 그건 다른 포스팅에서 정리해보록 하겠습니다. 그리고 Retrieval에 대한 개념이 생소하신 분들 위해서도 다른 포스팅에 정리해둘테니 참고해주시면 되겠습니다!
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}),
return_source_documents=True)
ChatOpenAI에서 model_name은 기본 모델인 gpt-3.5-turbo를 사용하고, 여기서 하나의 temperature=0이면 굉장히 보수적인 지문에만 있는 답변을 낼 수 있습니다. temperature=1일경우는 조금 더 다양한 답변을 낼 수 있으니 이것도 적절한 temperature을 사용해 조절하시면 됩니다!
RetrievalQA는 LangChain에서 제공하는 RetrievalQA를 사용했습니다. 여기서 사용하는 인자들에 대해서 살펴볼려고 하는데요. 이전에 생략한 내용들이 있는데요. 이전 코드에서는 문서에서 임베딩을 뽑고, 뽑은 임베딩을 LangChain에서 제공하는 Chromadb로 넘겨 vectorstore를 생성했습니다. 넘겨진 vectorstore안에서 검색을 수행해야하는데요. 그 부분이 db.as_retriever부분입니다. 텍스트를 검색하려면 serach_type은 similarity와 mmr 두 가지 검색 유형이 있습니다.
- serch_type="similarity"는 retrieval 객체에서 유사성 검색을 사용하여, 질문 벡터와 가장 유사한 문장 벡터를 선택하는 유형입니다.
- serch_type="mmr"은 쿼리와의 유사성과 선택된 문서들 간의 다양성을 모두 최적화하는 maximum marginal relevance(mmr)검색을 사용합니다.
serch_kwargs옵션은 벡터저장소에서 프롬프트 3개의 텍스트 덩어리를 보내려는 것을 의미합니다. 더 많은 프롬프트를 보내시려면 숫자를 크게 잡으셔도 상관이없는데요. 과도하게 보내게된다면 OpenAI프롬프트 토큰 한도를 과도하게 사용하게 됩니다. 하지만 정보가 많을수록 답변이 더 정확해지기 때문에 여러 실험후, 괜찮은 매개변수를 선택하시면 되겠습니다!
return_source_documents는 source document로 사용한 문서를 반환할지 말지 결정하는 인수인데, True하면 source로 사용된 문서들을 보실 수 있습니다.
여기까지 LangChain retrievalQA에 대해 살펴보았고 기본적으로 RAG를 수행하기 위해서는 문서를 embedding해서 vectorstore에 저장해서 해당 vectorstore에 넘겨진 문서를 기반으로 QA를 어떻게 진행하는지에 대해서 살펴보았습니다!
'LLM > LangChain' 카테고리의 다른 글
| LangChain에서 문서를 분할할수있는 여러가지 TextSplitter (2) | 2023.11.19 |
|---|