
Abstract
최근 Transformer 및 Convolution neural network(CNN) 기반 모델은 Automatic Speech Recognition(ASR)에서 유망한 결과를 보여 주기 때문에 Recurrent neural networks (RNN)을 능가한다. Transformer 모델은 content-based global interactions을 잘 포착하는 반면, CNN은 local feature을 효과적으로 활용한다.
본 연구에서는 Convolution neural network과 Transformer를 결합하여 오디오 시퀀스의 local 및 global 의존성을 매개 변수 효율적인 방식으로 모델링하는 방법을 연구하여 양쪽 모두 최고를 달성한다. 이와 관련하여, 우리는 conformer라는 음성 인식을 위한 convolution-augmented transformer를 제안한다. conformer는 최첨단 정확도를 달성하는 이전 transformer 및 CNN 기반 모델을 크게 능가한다. 널리 사용되는 LibriSpeech 벤치마크에서 우리 모델은 언어 모델을 사용하지 않고 2.1%/4.3%, test/testother에서 외부 언어 모델을 사용하여 1.9%/3.9%의 WER을 달성했습니다. 우리는 또한 10M 매개변수의 작은 모델로 2.7%/6.3%의 경쟁 성능을 관찰합니다.
1. Introduction
신경망을 기반으로 한 End-to-end automatic speech recognition (ASR) 시스템은 최근 몇 년 동안 크게 개선되었다. Recurrent neural networks (RNN)은 오디오 시퀀스의 시간 의존성을 효과적으로 모델링할 수 있기 때문에 ASR[1, 2, 3, 4]에 대한 실질적인 선택이었다[5]. 최근 self-attention를 기반으로 한 Transformer 아키텍처[6, 7]는 장거리 상호 작용을 캡처할 수 있고 높은 training 효율성으로 인해 모델링 시퀀스에 널리 채택되고 있다. 대안으로, ASR [8, 9, 10, 11, 12]에서도 convolutions은 성공적이었다. ASR은 local receptive field layer를 통해 점진적으로 local context를 캡처합니다.
그러나 self-attention이나 convolutions모델은 각각 한계가 있습니다. Transformer은 long-range global context를 모델링하는데 좋지만, fine-grained local featrue pattern을 추출하는 능력은 떨어집니다. 반면에 Convolution neural network (CNN)은 local 정보를 활용하고 vision에서 사실상의 계산 블록으로 사용됩니다. 그들은 번역 동등성을 유지하고, 가장자리 및 모양과 같은 feature을 캡쳐할 수 있는 local window를 통해 공유된 위치 기반의 kernel을 학습합니다. local 연결성을 사용할 때에 한 가지 제한사항은 global 정보를 캡쳐하려면 더 많은 layer 또는 매개변수가 필요 하다는 것입니다. 이 문제를 해결하기 위해서 동시대의 논문 ContextNet [10]은 각 residual block에 squeeze와 excitation을 채택하여 더 긴 맥락을 포착합니다. 그러나 전체 시퀀스에 걸쳐 전역 평균만 적용하기 때문에 동적 글로벌 context를 캡쳐하는 데는 여전히 한계가 있습니다.
최근의 연구는 convolution과 self-attention의 결합과 이것들을 개별적으로 사용할 때보다 향상된다는 것을 보여주었습니다[14]. 이들은 함께 position-wise local feature을 학습하고, content-based global interactions을 사용할 수 있습니다. 동시에, [15, 16]과 같은 논문은 등변성(equivariance)을 유지하는 상대적 위치 기반의 정보로 self attention을 강화했습니다. Wu 외 연구진[17]은 입력을 두 개의 branch (즉. self attention과 convolution) 그리고 그 결과물을 연결하는 다중 branch 아키텍쳐를 제안하였습니다. 그들의 작업은 모바일 애플리케이션을 대상으로 했고, 기계 번역 작업의 향상을 보여주었습니다.
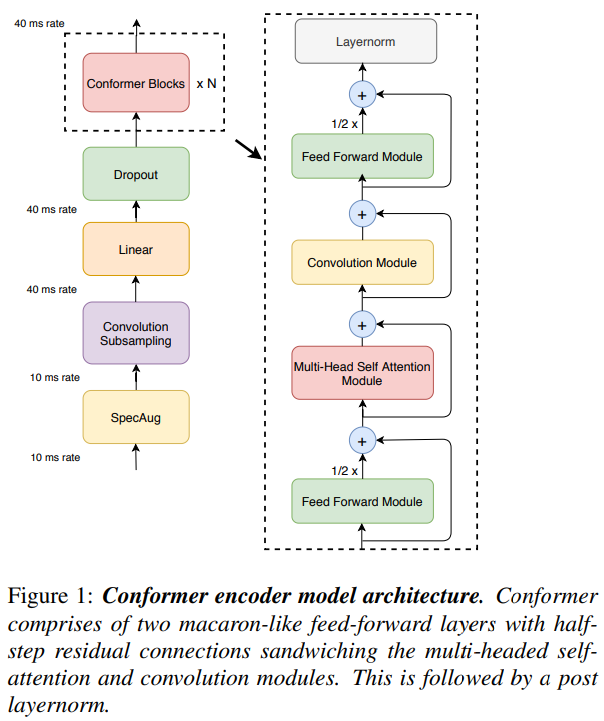
이 논문에서 우리는 ASR모델에서 convolution을 self attention과 유기적으로 결합하는 방법을 연구합니다. 우리는 global과 local 상호작용이 매개 변수 효율화를 위해 중요하다고 가정합니다. 이를 달성하기 위해, 우리는 self attention과 convolution의 새로운 조합을 제안합니다. self attention은 global 상호 작용을 학습하는 반면, convolution은 상대적 offset기반 local 상관관계를 효율적으로 포착합니다. Wu 외 연구진 [17, 18]에 의해 영감을 받아서, 우리는 그림 1에 설명된 것 처럼 pair feed forward modules 사이에 끼어 있는 self-attention과 convolution의 새로운 조합을 소개합니다.
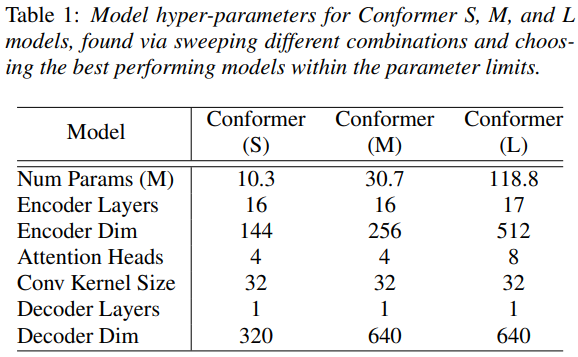
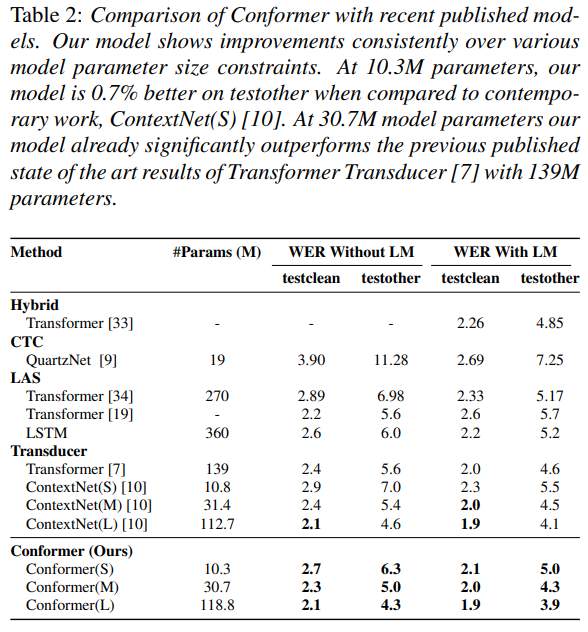
우리가 제안한 Conformer라는 이름의 모델은 LibriSpeech에서 최고의 결과를 달성하여 외부 언어 모델가진 testother 데이터셋에서 15%의 상대적인 개선으로 이전 성능이 좋은 걸로 출판된 Transformer Transducer[7]을 능가합니다. 우리는 10M, 30M, 118M의 모델 매개 변수 한계 제약 조건을 기반으로 세 가지 모델을 제시합니다. 우리의 10M 모델은 test/testother 데이터셋이 대해 2.7%/6.3%로 유사한 크기의 contemporary work[10]과 비교할 때 향상되었습니다. 우리의 중형 30M 매개 변수 크기의 모델은 이미 139M 모델 매개 변수를 사용하는 [7]에서 발표된 transformer를 능가합니다. 큰 118M 매개 변수 모델을 사용하면 언어 모델을 사용하지 않고도 2.1%, 외부 언어 모델을 사용하면 1.9%/3.9%를 달성할 수 있습니다.
우리는 attention head의 수, convolution kernel의 size, activation function, feed-forward layer의 배치 그리고 convolution 모듈을 Transformer기반 네트워크에 추가하는 다양한 전략의 영향을 추가로 연구하고 각각이 정확도 향상이 어떻게 기여하는지 연구합니다.
2. Conformer Encoder
우리의 오디오 인코더는 먼저 covolution subsampling layer로 input을 처리한 다음 그림 1과 같이 다수의 conformer block으로 입력을 처리합니다. 우리 모델의 독특한 특징은 [7, 19]에서와 같이 transformer block 대신에 conformer block을 사용하는 것입니다.
conformer block은 feed-forward 모듈, self-attention 모듈, convolution 모듈 그리고 마지막에 두번째 feed-forward 모듈로 구성된 네 개의 모듈로 구성됩니다. 섹션 2.1, 2.2, 2.3은 각각 self-attention, convolution 그리고 feed-forward 모듈을 소개합니다. 마지막으로 2.4에서는 이러한 하위 블록이 어떻게 결합되는지를 설명합니다.
2.1 Multi-Headed Self-Attention Module
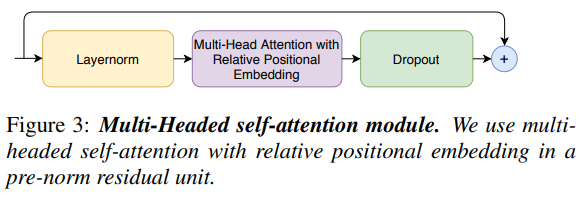
우리는 상대적인 sinusoidal positional 인코딩 체계인 Transformer-XL로부터 중요한 기술을 통합하면서 multi-headed self-attention(MHSA)를 사용합니다. relative positional encoding을 사용하면 self-attention 모듈이 다른 입력 길이에 더 잘 일반화할 수 있으며, 인코딩 결과는 utterance 길이의 분산에 더 강합니다. 우리는 더 깊은 모델을 훈련하고 정규화하는 데 도움이 되는 dropout과 함께 prenorm residual units [21, 22]을 사용합니다. 위의 그림 3은 multi-headed self-attention block을 보여줍니다.
* pre-norm [21, 22] : 기존 transformer는 post-norm인데 반해, conformer는 pre-norm을 적용해 이전 연구들에서 pre-norm은 깊은 모델 학습이 원활하게 하도록 도와주는 효과가 있다고 함.
* relative positional encoding : 절대적인 position정보를 더하는 방식이 아닌 상대적인 position정보를 주는 방식!
절대적인 position방식은 값을 직접 지정해주고 그 차이를 계산하는 방식이고, 상대적인 position 방식은 어떤 값이든지 그 값의 차이만 나게 알려주는 방식! ---> 가변적인 시퀀스 길이 input에 대해 encoder를 robust하게 만들어 줌!
2.2 Convolution Module

[17]에서 영감을 받은 convolution module은 pointwise convolution과 gated linear unit (GLU)인 gating machanism [23]에서 시작합니다. 그 다음에는 단일 1-D depthwise convolution layer가 이어집니다. batchnorm은 deep module 훈련을 지원하기 위해 convolution 직후 전개됩니다. 그림 2는 convolution block을 보여줍니다.
* Depthwise conv : 그룹이 채널 수와 같은 Group-Convolution이다. 각 채널마다 spatial feature를 추출하기 위해 고안된 방법!
2.3 Feed Forward Module
[6]에서 제안된 transformer 아키텍쳐는 MHSA layer 다음에 feed-forward 모듈을 배치하며, 두 개의 linear transformations 과 그 사이의 비선형 activation으로 구성됩니다. feed-forward layer 위에 residual connection이 추가된 다음 레이어 정규화가 수행됩니다. 이러한 구조는 또한 Transformer ASR 모델에서도 채택됩니다 [7, 24].
우리는 pre-norm residual units [21, 22]를 따르고, residual unit 내에서 그리고 첫 번째 linear layer 이전의 입력에 layer normalization을 적용합니다. 우리는 또한 네트워크를 정규화하는 데 도움이 되는 Swish activation[25]와 dropout을 적용합니다. 그림 4는 FFN(Feed Forward) 모듈을 나타냅니다.

# Swish activation function : regularizing에 도움을 주는 함수
def swish(x):
return x * torch.sigmoid(x)# Glu activation function
class GLU(nn.Module):
def __init__(self, in_size):
super().__init__()
self.linear1 = nn.Linear(in_size, in_size)
self.linear2 = nn.Linear(in_size, in_size)
def forward(self, x):
return self.linear1(x) * self.linear2(x).sigmoid()
2.4 Conformer Block
우리가 제안한 conformer block은 그림 1과 같이 multi-headed Self-Attention 모듈과 Convolution 모듈을 샌드위치화한 두 개의 feed-forward 모듈을 포함하고 있습니다.
이 샌드위치 구조는 Macaron-Net [18]에서 영감을 받아 transformer block의 원래 feed-forward layer를 attention layer 앞과 후에 두 개의 half step feed-forward layer로 교체할 것을 제안합니다. Macron-Net과 마찬가지로 Feed-Forward (FFN) module에 half-step residual 가중치를 사용합니다. 두 번째 feed-forward module은 최종 layernorm layer가 뒤따릅니다. 수학적으로 이것은 conformer block i에 대한 입력 xi에 대한 블록의 출력 yi는 다음과 같습니다.
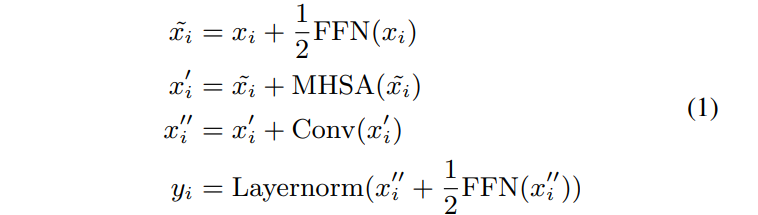
3. Experiments
3.1 Data
3.2 Conformer Transducer
3.3 Results on LibriSpeech
3.4 Ablation Studies
3.4.1. Conformer Block vs. Transformer Block
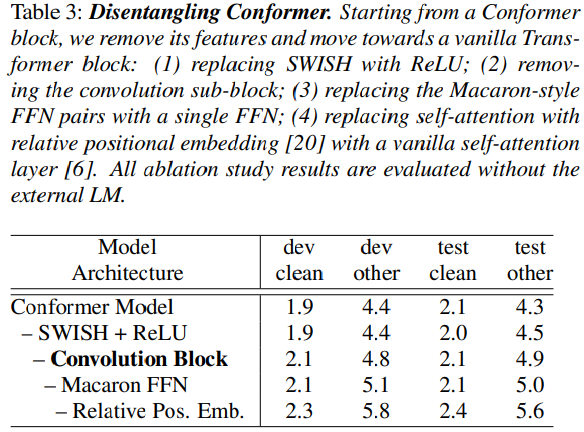
coformer block은 특히 convolution block을 포함하고 Macaron-style의 block을 둘러싸는 한 쌍의 FFN을 갖는 등 여러 면에서 transformer block과 다릅니다. 아래에서는 총 매개 변수 수를 변경하지 않고 Conformer block을 Transformer block으로 변경함으로써 이러한 차이의 효과를 연구합니다. 표 3은 conformer block에 대한 각 변경의 영향을 보여줍니다. 모든 차이점 중에서 convolution 하위 블록이 가장 중요한 특징이며, Macaron-style FFN 쌍을 갖는 것도 동일한 수의 매개 변수의 단일 FFN보다 더 효과적입니다. swish activation을 사용하면 conformer의 수렴이 더 빨라집니다.
3.4.2 Combinations of Convolution and Transformer Modules
우리는 multi-headed self-attention (MHSA) 모듈과 convolution module을 결합하는 다양한 방법의 효과를 연구합니다. 먼저 convolution module의 depthwise convolution을 lightweight convolution [35]로 교체하려고 합니다. 특히 devother 데이터셋에서 성능이 크게 저하되는 것을 보아야합니다.
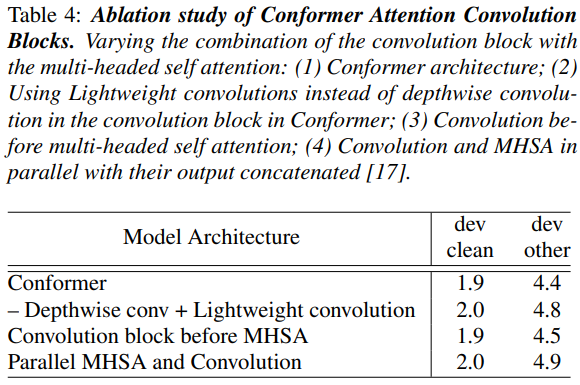
둘째, conformer model에서 MHSA 모듈 앞에 convolution module을 배치하는 것을 연구하여 개발 시 0.1까지 결과를 저하시킵니다. 아키텍처의 또 다른 가능한 방법은 입력을 multi-headed self attention module과 이들의 출력이 연결된 convolution module의 병렬 지점으로 분할 하는 것입니다 [17]. 제안된 아키텍처에 비해 성능이 저하된다는 것을 발견했습니다. 표 4의 이러한 결과는 conformer block의 self-attention module 다음에 convolution module을 배치할 때의 장점을 보여줍니다.
3.4.3 Macaron Feed Forward Modules
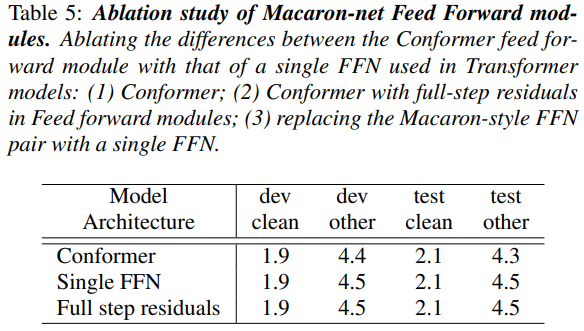
단일 feed-forward module (FFN)이 transformer 모델에서처럼 attention block을 게시하는 대신 conformer block에는 self-attention 및 convolution model을 샌드위치화하는 macaron과 같은 feed-forward 모듈이 있습니다. 또한, Conformer feed-forward모듈은 half-step residual와 함께 사용됩니다. 표 5는 단일 FFN 또는 full-step residual을 사용하도록 conformer block을 변경할 때의 영향을 보여줍니다.
3.4.4 Number of Attention Heads
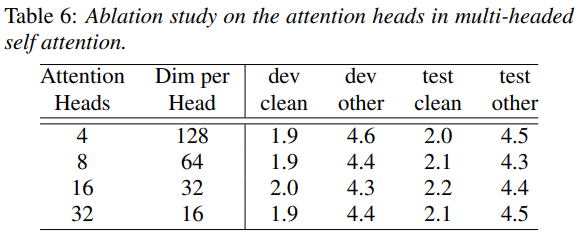
self-attention에서 각 attention head는 입력의 서로 다른 부분을 집중하는 법을 배워서 단순한 weighted average를 넘어 예측을 개선할 수 있습니다. 우리는 모든 layer에서 동일한 수의 헤드를 사용하여 대형 모델에서 attention head의 수를 4개에서 32개로 변화시키는 효과를 연구하기 위한 실험을 수행합니다. 우리는 attention head를 최대 16개까지 증가시키면 특히 표 6과 같이 다른 데이터 세트에 비해 정확도가 향상된다는 것을 발견했습니다.
3.4.5 Convolution Kernel Sizes

depthwise convolution에서 커널 크기의 영향을 연구하기 위해 모든 layer에 대해 동일한 커널 크기를 사용하여 대형 모델의 {3, 7, 17, 32, 65}에서 커널 크기를 스위프합니다. 커널 크기 17과 32까지는 커널 크기가 클수록 성능이 향상되지만, 표 7과 같이 커널 크기 65의 경우 성능이 악화됩니다. dev WER에서 두 번째 소수점을 비교하면 커널 크기 32가 나머지보다 성능이 우수하다는 것을 알 수 있습니다.
4. Conclusion
본 연구에서는 종단 간 음성 인식을 이해 CNN과 transformer의 구성 요소를 통합하는 아키텍처인 conformer를 소개하였습니다. 우리는 각 구성 요소의 중요성을 연구했고, conformer 모델의 성능에 convoluton module의 포함이 중요하다는 것을 입증했습니다 이 모델은 LibriSpeech 데이터셋에 대해 이전 연구보다 적은 매개변수로 더 나은 정확도를 보이며 test/testother의 경우 1.9%/3.9%로 새로운 최첨단 성능을 달성합니다.
'Paper > Speech Recognition' 카테고리의 다른 글
| [SR paper] Whisper - Robust Speech Recognition via Large-Scale Weak Supervision 파헤쳐보기 (2) | 2023.11.14 |
|---|