
논문 읽기 위한 기본 지식 내용
- Speech enhancement란?
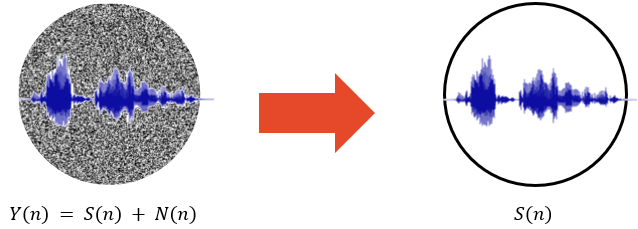
위의 그림은 기본적인 speech enhancement task를 time domain에서의 그림으로 표현한 것입니다. 파란색의 음성파형은 우리가 관심있는 clean speech (S(n))이고, 뒤에 배경은 noise (N(n))입니다. 이렇게 clean speech와 noise가 섞여 있는 상태를 noisy speech (Y(n))라고 부릅니다. speech enhancement는 noise와 clean speech가 섞여있는 noisy한 환경에서 noise를 제거하고 clean speech만 추출하는 것이 목표입니다. 본문에서는 clean speech와 nosie가 섞여있는 noisy한 환경을 mixture라고 부릅니다.
Abstract
Speech Separation은 noisy가 있는 음성의 STFT(Short-Time Fourier Transform)에서 작동하며, phase 스펙트럼은 사용하지 않고, magnitude 스펙트럼만을 사용해 향상합니다. 그 이유는 phase 스펙트럼이 speech enhancement에 중요하지 않다고 생각하였기에 phase를 빼고 수행하였으나, 최근 연구에 따르면, phase는 perceptual quality에 중요하므로 일부 연구자는 magnitude와 phase 스펙트럼 둘다 향상시키는 것을 고려했습니다.
우리는 complex domain에서 작동해서 magnitude와 phase 스펙트럼을 동시에 향상시키는 supervised monaural speech separation접근방식을 제시합니다. 접근 방식은 complex domain에서 정의된 ideal ratio mask의 real과 imaginary 요소를 추정하기 위해 Deep neural networks를 사용합니다. 제안된 방법에 대한 separation결과를 보고하고, 관련 시스템과 비교합니다.
제안된 접근 방식은 PESQ(Perceptual Assessment of Speech quality) 및 피험자가 제안된 접근 방식을 69% 이상 선호하는 청취 테스트를 포함하여 여러 객관적 메트릭으로 평가할 때 다른 방법보다 향상됩니다.
1. Introduction
noisy한 환경에서 noise를 제거하는 것은 speech processing분야에서 가장 challenging한 연구 주제 중 하나로 고려됩니다. 오직 single microphone에서 signal만 획득해야하는 monaural case에서 훨씬 더 challenging합니다. 비록 monaural speech separation에서 많은 개선이 있었지만, 여전히 고품질로 분리된 speech를 생성해야할 강한 요구가 있습니다.
일반적인 speech separation systems은 [1], [2]의 연구결과로 phase response를 사용하지 않고, magnitude respose만을 향상시킴으로써, time-frequency (T-F) domain에서 작동합니다. [1]에서 speech quality측면에서 phase 및 magnitude 구성 요소의 상대적 중요성을 결정하기 위해 일련의 실험이 수행되었습니다. Wang과 Lim은 특정 signal-to-noise ratio (SNR)에서 noisy 음성의 푸리에 변환 magnitude response를 계산한 다음 다른 SNR에서 생성된 푸리에 변환 phase response과 결합하여 테스트 신호를 재구성합니다. 그런 다음 청취자는 재구성된 각 신호를 알려진 SNR의 처리되지 않은 noisy speech와 비교하고 어떤 신호가 가장 잘 들리는지 나타냅니다. phase와 magnitude spectra의 상대적 중요도는 동등한 SNR을 정량화되며, 이는 재구성된 speech 및 noise가 각각 50%비율로 선택되는 SNR입니다. 결과들은 magnitude response보다 훨씬 높은 SNR을 사용하여 phase response를 재구성할 경우 동등한 SNR에서 상당한 개선이 얻어지지 않는다는 것을 보여줍니다. 이러한 결과는 이전 연구의 결과와 일치합니다[3]. Ephraim과 Malah[2]는 magnitude response에 대한 MMSE 추정값과 phase response의 complex exponential로 구성된 clean spectrum을 추정하기 위해 minimum mean-square error (MMSE)를 사용해 speech를 noise와 분리합니다. 이들은 noisy phase의 complex exponential가 clean phase의 complex exponential에 대한 MMSE 추정치임을 보여줍니다. clean spectrum의 MMSE 추정치는 clean magnitude spectrum의 MMSE추정치와 noisy phase의 complex exponential의 곱으로, phase가 signal 재구성을 위해 변경되지 않았음을 의미합니다.
그러나, Paliwal [4]등의 최근 연구는 phase spectrum만 강화되고 noisy magnitude spectrum은 바뀌지 않을 때 perceptual quality 개선이 가능하다는 것을 보여줍니다. Paliwal등은 noisy magnitude response를 oracle (즉, clean) phase, 비 oracle (즉, noisy) phase 및 매칭되지않은 shor time Fourier transform (STFT) 분석 windows를 사용하여 magnitude와 phase spectra를 추출하는 향상된 phase와 결합합니다. 개선점을 평가하기 위해 객관적이고 주관적인 (즉, listening study) speech quality 측정을 모두 사용합니다. 듣는 평가는 signal 쌍 사이의 선호도 선택이 포함됩니다. 결과에 따르면 oracle phase spectrum이 noisy magnitude spectrum에 적용하면 상당한 음성 품질이 가능한 반면, 비 oracle phase를 사용하면 약간 개선됩니다. clean magnitude spectrum의 MMSE 추정치를 oracle 및 비 oracle phase response와 결합할 경우 결과는 유사합니다. 또한, clean magnitude spectrum의 MMSE 추정치를 향상된 phase response와 결합하면 높은 선호도 점수가 달성됩니다.
Paliwal에 의한 연구는 일부 연구자들이 speech separation [5]-[7]을 위한 phase enhancement 알고리즘을 개발하기 위해 이끕니다. [5]에서 제시된 시스템은 multiple input spectrogram inversions (MISI)을 사용하여 해당 추정된 STFT magnitude response를 고려하여 mixture의 time domain source singnal을 반복적으로 추정합니다. Spectrogram inversion은 magnitude response를 제한하면서 누락된 phase정보를 반복적으로 복구하여 신호를 추정합니다. MISI는 mixture과 추정된 sources의 합 사이의 평균 총 오차를 사용하여 각 반복마다 source 추정치를 업데이트하는데에 사용합니다. [6]에서 Mowlaee등은 mixture의 두 sources의 phase가 제곱 오차를 최소화하여 추정되는 MMSE phase 추정을 수행합니다. 이러한 최소화로 인해 여러 phase 후보가 생성되지만, 궁극적으로 그룹 지연이 가장 낮은 phase의 쌍을 선택합니다. 그런 다음 sources는 magnitude response 및 추정된 phase으로 재구성됩니다. Krawczyk와 Gerkmann[7]는 기본 주파수의 추정치에 따라 주파수와 시간에 걸쳐 harmonic 성분 사이의 phase를 재구성하여 voiced-speech 프레임의 phase를 향상시킵니다. Unvoiced 프레임은 변화되지 않은 상태로 유지됩니다. [5]-[7]의 접근법은 phase가 강화될 때, 객관적인 품질 개선을 보여줍니다. 그러나 magnitude response는 다루지 않습니다.
phase 추정을 검토하도록 동기를 부여하는 또 다른 요인은 supervised mask 추정이 최근 매우 noisy 조건에서 인간 음성 이해성을 향상시키는 것으로 나타났다는 것입니다 [8], [9]. 음의 SNR의 경우, noisy 음성의 phase는 target speech보다 배경 잡음의 phase를 더 많이 반영합니다. 결과적으로, 향상된 음성을 재구성에서 noisy speech의 phase를 사용하는 것은 더 높은 SNR 조건[10]에서보다 더 문제가 됩니다. 따라서 어떤 면에서 매우 낮은 SNR에서 magnitude 추정의 성공은 이러한 SNR레벨에서 phase 추정의 필요성을 높입니다.
최근에, ideal ratio mask (IRM)을 추정하는 deep neural network (DNN)이 예측된 음성 지능[11] 외에도 객관적인 음성 품질을 향상시키는 것으로 나타났습니다. IRM은 noisy가 있는 speech의 magnitude response를 향상시키지만, 재구성을 위해 처리되지 않은 noisy phase를 사용합니다. phase enhancement 연구에 따르면, magnitude와 phase response가 모두 강화되면 ratio masking 결과가 더욱 개선되어야 합니다. 사실 최근 방법에 따르면 일부 phase 정보를 통합하는 것이 유익합니다 [12], [13]. [12]에서 clean speech와 noisy speech사이의 phase difference의 cosine이 IRM추정에 적용됩니다. Wang과 Wang[13]은 T-F masking을 위한 subnet과 inverse fast Fourier transform (IFFT)를 수행하는 다른 subnet을 결합하여 clean time domain signal을 추정합니다.
이 논문에서 우리는 complex ideal ratio mask (cIRM)을 정의하고, real과 imaginary 구성요소를 같이 추정하기 위해 DNN을 훈련시킵니다. complex domain에서 작동함으로서, cIRM은 noisy speech의 phase response와 magnitude 동시에 향상시킬 수 있습니다. listening study의 객관적인 결과와 선호도 점수는 cIRM 추정이 관련 방법보다 더 높은 품질의 음성을 생성한다는 것을 보여줍니다.
논문의 나머지는 다음와 같이 구성되어 있습니다. 다음 section에서 우리는 STFT의 real과 imaginary 구성 요소 내의 구조를 공개합니다. 섹션 3에서 cIRM에 대해 설명하고, 실험결과는 섹션 4에 나와 있습니다. 섹션 5에서 논의하면서 마무리합니다.
2. Structure within Short-time Fourier Transform
극 좌표 (magnitude와 phase)는 (1)에서 정의한 바와 같이 noisy speech STFT를 개선할 때, 일반적으로 사용됩니다.
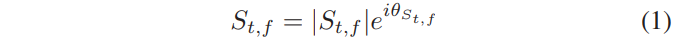
∣St,f∣는 magnitude response를 나타내고, θst,f 시간 t와 주파수f에 STFT의 phase response을 나타낸다. STFT representation에서 각 T-F unit은 real과 imaginary 요소를 가진 complex number이다. magnitude와 phase response은 real과 imaginary 요소로부터 아래와 같이 즉시 계산됩니다.
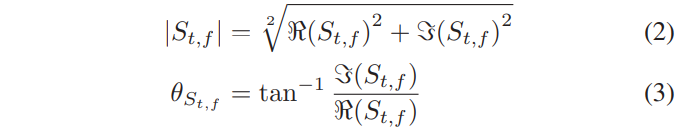
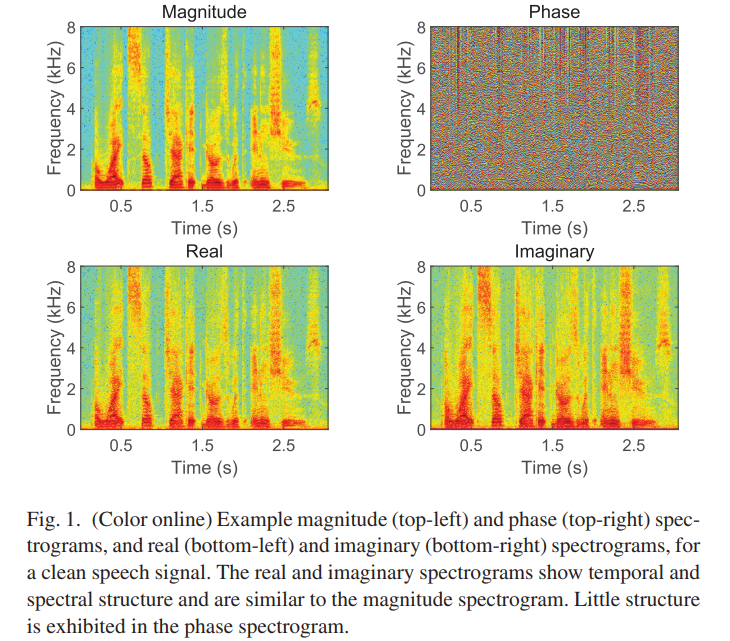
clean speech signal에 대한 magnitude(왼쪽 상단) 및 phase(오른쪽 상단) response의 예가 그림 1에 나와 있습니다. magnitude response은 명확한 시간적 및 spectrum 구조를 보이는 반면 phase response은 다소 무작위처럼 보입니다. 이는 종종 phase 값을 [-π, π]범위로 wrapping하기 때문입니다. learning 알고리즘을 사용하여 feature을 훈련 target에 매핑할 때, 매핑 함수에 구조가 있는 것이 중요하다. Fig 1은 noisy magnitude spectrum에서 clean magnitude spectrum을 학습하는 데 DNN의 성공에도 불구하고 DNN을 사용해 clean phase response를 직접 예측하는 것은 효과적이지 않다는 것을 보여줍니다. 실제로, 우리는 noisy speech으로부터 clean phase를 추정하도록 DNN을 훈련시키기 위해 광범위하게 노력했지만 성공적이지 못했습니다.
극 좌표를 사용하는 것의 대안으로 (1)에서 STFT의 정의는 complex exponential의 확장을 사용하여 Cartesian 좌표로 표현될 수 있습니다. 이것은 STFT의 real 및 imaginary 요소에 대한 다음과 같은 정의로 이어지게됩니다.
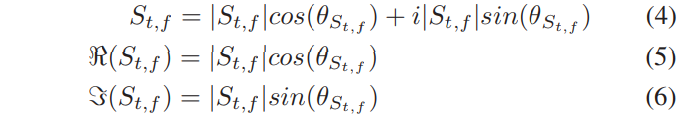
그림 1의 하단에는 clean speech의 real (왼쪽 하단) 및 imaginary (오른쪽 하단) spectrum의 log 압축된 절대값이 표시됩니다. real과 imaginary 구성요소 모두 magnitude spectrum과 유사한 명확한 구조를 보여주므로 supervised learning에 적합합니다. 이 스펙트럼들은 삼각 co-function때문에 거의 같이 보입니다. 사인 함수는 π/2라디안의 phase shift를 갖는 코사인 함수와 동일합니다. (2) 및 (3) 방정식은 magnitude와 phase response를 STFT의 real 및 imaginary 구성 요소에서 직접 계산할 수 있으므로 real 및 imaginary 구성 요소를 강화하면 magnitude 및 phase spectrum이 향상된다는 것을 보여줍니다.
이 구조를 기반으로하여 간단한 아이디어는 DNN을 사용하여 STFT의 복잡한 구성 요소를 예측하는 것입니다. 그러나, 최근 연구에 따르면 magnitude spectrum을 직접 예측하는 것이 ideal T-F mask [11]을 예측하는 것만큼 좋지 않을 수 있습니다. 따라서 다음 절에서 설명하는 complex ideal ratio mask의 real 및 imaginary 성분을 예측한 것을 제안합니다.
3. Complex Ideal Ratio Mask and its Estimation
A. Mathematical Derivation (수학적인 유도)
기존의 ideal ratio mask는 magnitude domain에서 정의되며, 이 섹션에서는 complex domain에서 ideal ratio mask를 정의합니다. 우리의 목표는 noisy speech의 STFT에 적용될 때, clean speech의 STFT를 생성하는 complex ratio mask를 도출하는 것입니다. 다시 말하면, noisy speech Ytf가 주어졌을 때, 우리는 다음과 같이 clean speech의 complex spectrum Stf를 얻습니다.
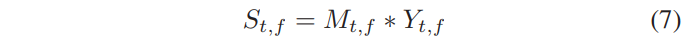
'*'은 complex multiplication을 나타내며, Mtf은 cIRM입니다. Ytf, Stf와 Mtf는 complex number이며, 다음과 같이 직사각형 형태로 쓸 수 있습니다.
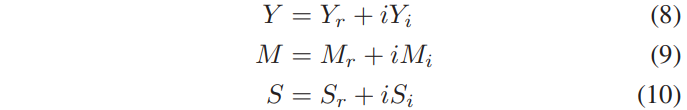
여기서 첨자 r과 i는 각각 real과 imaginary 성분을 나타냅니다. 시간과 주파수에 대한 첨자는 편의를 위해 표시되어 있지 않지만, 각 T-F단위로 정의가 됩니다. 이러한 정의에 따라. Eq. (7)을 확장할 수 있습니다.
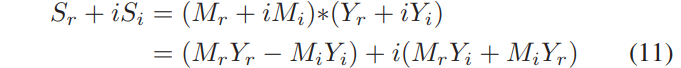
여기서부터 clean speech의 real과 imaginary의 성분들이 다음과 같이 주어진다라는 결론을 내릴 수 있습니다.
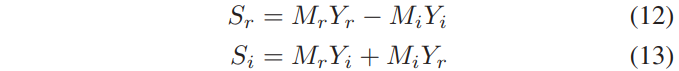
Eq (12)와 (13)을 사용하여 M의 real과 imaginary 성분은 다음과 같이 정의됩니다.
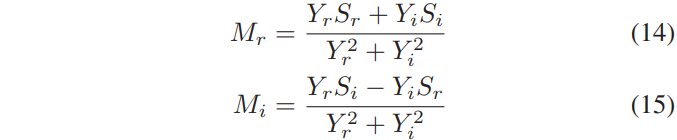
결과적으로 complex ideal ratio mask에 대한 정의가 발생합니다.
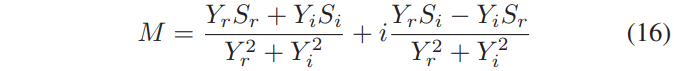
이 complex ideal ratio mask의 정의는 noisy speech의 power spectrum [14]에서 noisy와 clean speech의 cross-power spectrum의 complex ration인 Wiener filter와 굉장히 연관되어있습니다. Sr,Si,Yr과 Yi∈R은 Mr 및 Mi∈R을 의미한다는 점을 언급하는 것이 중요합니다. 이를 통해 complex mask는 (-∞,∞)범위의 값을 같는 큰 real 및 imaginary성분을 가질 수 있습니다. IRM은 [0,1] 범위의 값을 가지며, DNN을 통한 supervised learning에 도움이 될 수 있음을 기억합시다. 값 범위가 크면 cIRM 추정이 복잡해질 수 있습니다. 따라서 우리는 아래와 같이 hyperbolic tangent으로 cIRM을 압축합니다.
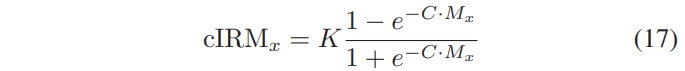
여기서 x는 r또는 i이며, real 및 imaginary성분을 나타냅니다. 이 압축은 [-K, K]내에서 마스크값을 생성하며 C는 그 경사를 제어합니다. K 및 C에 대한 여러 값이 평가되며, K=10 및 C=0.1은 경험적으로 가장 잘 수행되며, DNN을 훈련하는 데 사용됩니다. 테스트 하는 동안 DNN출력에서 다음 역함수 Ox를 사용하여 압축되지 않은 마스크의 추정치를 복구합니다.
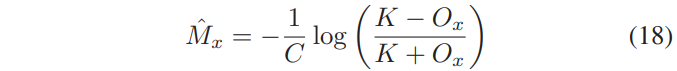
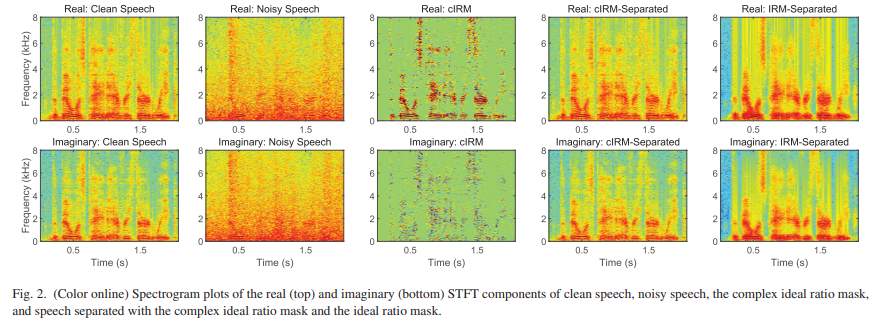
cIRM의 예는 clean, noisy, cIRM으로 분리된, IRM으로 분리된 speech의 spectrum과 함께 Fig2에서 보여줍니다. 각 signal의 complex STFT의 real 부분은 상단에 보여주고, imaginary 부분은 그림의 하단에 있습니다. noisy speech는 clean speech signal과 0dB SNR에 Factory noise를 결합하여 생성됩니다. 이 예제에서 cIRM은 (17)에서 K=1로 생성됩니다. denoised speech signal은 cIRM과 noisy speech의 곱을 취함으로써 계산됩니다. denoised signal은 clean speech와 비교하여 효과적으로 재구성됩니다. 반면에, IRM으로 분리된 speech는 noise의 많은 부분을 제거하지만, cIRM으로 분리된 음성은 clean speech 신호와 real 및 imaginary 성분을 재구성하지 않습니다.
B. DNN Based cIRM Estimation
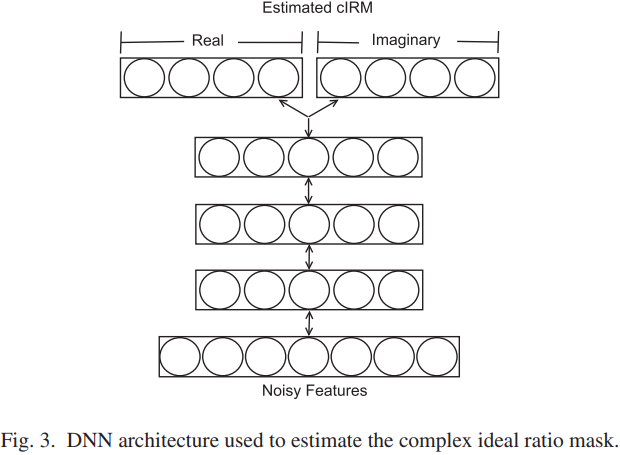
cIRM 추정에 사용되는 DNN은 Fig3에 설명되어 있습니다. 이전 연구에서와 같이 [11], [15], DNN에는 각각의 hidden layer가 동일한 수의 units을 갖는 세 개의 hidden layer가 있습니다.
입력 레이어에는 64채널 gammaton filterbank에서 추출된 다음과 같은 보완 feature set가 제공됩니다.
- Amplitude modulatin spectrogram (AMS)
- Relative spectral transform and perceptual linear prediction (RASTA-PLP)
- mel-frequency cepstral coefficients (MFCC)
- cochleagram response (달팽기관 반응) 뿐만 아니라 delta
사용된 feature는 [11]에서와 동일합니다. 이러한 특징의 조합은 speech segregation [16]에서 효과적인 것으로 나타납니다. 또한, noisy magnitude, noisy magnitude와 phase 그리고 noisy STFT의 real과 imaginary 성분을 포함한 다른 feature도 평가했지만, 보완 set만큼 좋지 못했습니다. 유용한 정보는 time 프레임에 걸쳐 전달되므로, 슬라이딩 context window을 사용하여 인접한 프레임을 각 time 프레임[11], [17]의 단일 feature vector로 연결하는 데 사용됩니다. 이것은 DNN의 입력과 출력에 사용됩니다. 즉, DNN은 보완 feature의 프레임의 window를 각 time 프레임에 대해 cIRM의 widow의 프레임에 매핑합니다. output layer는 cIRM의 real 성분을 위한 cIRM의 imaginary 성분을 위한 두 개의 하위 계층으로 분리 된다는 점에 주목합시다. output layer에서 Y자 네트워크 구조는 일반적으로 관련 targets [18]을 함께 추정하는 데 사용되며, 이 경우 real 및 imaginary 성분이 동일한 입력 feature로부터 함께 추정되도록 하는 데 도움이 됩니다.
이 네트워크 구조의 경우, complex 데이터에 대한 mean-square error (MSE) 함수는 역 전파 알고리즘에서 DNN 가중치를 업데이트 하는 데 사용됩니다. 이 cost function은 아래와 같이 real data에서 MSE를 imaginary에서 MSE를 합한 것입니다.
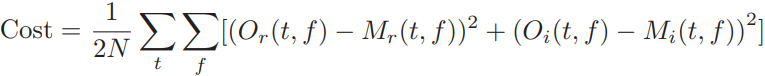
- N은 input에 대한 time frame의 수
- Or(t,f)와 Oi(t,f)는 T-F unit에서 DNN에서 real과 imaginary output을 의미
- Mr(t,f)와 Mi(t,f)는 상대적으로 cIRM의 real과 imaginary성분들에 해당한다.
- 각 DNN hidden layer : 1024 units [11].
- hidden layer에 대해서는 rectified linear (ReLU) activation function 사용
- output layer에 대해서는 linear units을 사용 (cIRM이 0과 1사이 경계를 두지 않기 때문에..)
- Optimization : momentum term을 가진 Adaptive gradient descent [20]
- momentum rate은 처음 5 epochs는 0.5로 설정, 나머지 75 epochs에서 0.9로 변경해서 사용 (총 80epochs)
4. Results
A. Dataset and System Setup
제안된 시스템은 single male speaker에 의해 720 utterance spoken으로 구성된 IEEE database[21]로 평가됩니다. testing set는 16kHz로 다운샘플링된 60개의 clean utterance로 구성됩니다.
각 testing utterance를 만드는데 사용된 noise가 아래 4가지로 사용되었습니다.
- Speech-shaped noise (SSN)
- Cafeteria (Cafe)
- Speech babble (Babble)
- Factory floor noise (Factory)
-6, -3, 0, 3, 6dB의 SNR에 위의 4가지 noise들이 섞여서 testing utterance가 만들어졌다.
결과적으로 1200 (60 signal x 4 noises x 5 SNRs) mixtures로 만들어진다.
SSN은 stationary noise, 다른 noise는 non-stationary하다. 각각의 signal은 약 4분이다. 각 noise의 마지막 2분 동안의 random 컷을 각 테스트 utterance와 혼합하여 test mixture을 만듭니다. cIRM 추정을 위한 DNN은 test utterance와 다른 IEEE 말뭉치의 500개의 utterance로 훈련됩니다. 각 noise의 처음 2분동안 10개의 random 컷을 각 훈련 utterance과 혼합하여 훈련 세트를 생성합니다. DNN을 위한 mixture는 -3,0,3dB SNR에서 생성되며, 훈련 세트에서 60000 (500 signal x 4 noise x 10 random cut x 3 SNR) mixture이 생성됩니다. test mixture의 -6 및 6dB SNR은 훈련 중에 DNN에 의해 보이지 않습니다. 노이즈를 두 부분으로 나누면 test noise segment가 training 중에 보이지 않습니다. 또한 development set은 DNN 및 STFT에 대한 파라미터 값을 결정합니다. 이 development set은 -3, 0, 3dB의 SNR에서 위의 4가지 noise 중 처음 2분 동안 random cut이 혼합된 50개의 개별 clean IEEE utterances로부터 생성됩니다.
게다가 많은 남성과 여성 speaker들의 utterances로 구성된 TIMIT corpus [22]를 사용합니다. DNN은 -3, 0 및 3dB의 SNR에서 500개의 utterances (50개의 speakers에서 10개의 utterances)와 위의 noise를 혼합하여 훈련합니다. 훈련 utterances은 35명의 남성과 15명의 여성 speakers들이 합니다. 60개의 다른 utterances (6명의 새로운 speaker에서 10개의 utterances)이 test에 사용됩니다. test utterances은 남성 4명과 여성 2명으로부터 나왔습니다.
섹션 3-B에 기술된 바와 같이 4가지 feature의 보완 세트가 DNN에 입력으로 제공됩니다. 일단 보완 feature가 noisy speech로부터 계산되면, 각 주파수 채널에서 0의 평균과 unit variance를 갖도록 정규화시킵니다. auto-regressive moving average (ARMA) 필터링을 입력 feature에 적용하면 ARMA 필터링이 시간 경과에 따라 각 feature 차원을 부드럽게(smooth)하게 하여 배경 잡음의 interference(간섭)을 감소시키기 때문에 자동 음성 인식 성능이 향상된 다는 것이 [23]에 나와있습니다. 또한, ARMA 필터는 음성 분리 결과 [24]를 개선합니다. 따라서, 평균 및 분산 정규화 후 complementary set(보완 세트)의 feature에 ARMA 필터링을 적용합니다. 현재 time 프레임에 ARMA 필터링된 feature 벡터는 현재 프레임과 함께 현재 프레임 앞에 있는 두 개의 필터링된 feature 벡터와 현재 프레임 뒤에 필터링 되지 않은 두 개의 feature 벡터의 평균을 산출하여 계산합니다. 5개 프레임(전 2개, 후 2개)에 걸쳐 있는 context window은 ARMA 필터링된 feature을 입력 feature 벡터로 연결합니다.
DNN은 (16)과 (17)에 설명된 대로 cIRM이 noisy와 clean speech의 STFT에서 생성되는 각 훈련 mixture에 대한 cIRM을 추정하도록 훈련합니다. STFT는 인접 프레임 간의 50% overlap을 사용하여 time domain signal을 40ms(640 sample) 겹치는 프레임으로 분할하여 생성합니다. 640 길이의 FFT와 함께 Hann window가 사용됩니다. 3 프레임의 context window은 출력 레이어에 대해 cIRM의 각 프레임을 증강시키며, 이는 DNN이 각 입력 feature vector에 대해 3 프레임으로 추정한다는 것을 의미합니다.
B. Comparison Methods
우리는 IRM [11] 추정, phase-sensitive masking (PSM) [12], time-domain signal reconstruction (TDR) [13], complex-domain nonnegative matrix factorization (CMF) [25]-[27]을 cIRM추정과 비교합니다. IRM 추정과 비교하는 것은 complex 도메인에서의 처리가 magnitude domain에서 처리보다 개선되는지 여부를 결정되는 데 도움이 되며, 다른 비교는 phase 정도를 통합하는 이러한 최근 supervised방법과 비교하여 complex ratio masking이 수행되는 방식을 결정하는 데 도움이 됩니다.
- Ideal Ratio Masking (IRM)은 각 T-F단위에서 speech와 noise 에너지의 합에 대한 speech 에너지 비율의 제곱근을 구함으로써 생성됩니다 [11]. IRM을 추정하기 위해 별도의 DNN이 사용됩니다. 입력 feature과 DNN 매개 변수는 cIRM 추정에 대한 매개변수와 일치하지만 출력 레이어가 real 및 imaginary 성분이 아닌 magnitude에 해당한다는 점을 제외하고 cIRM 추정을 위한 매개변수와 일치합니다. IRM이 추정되면, noise phase와 함께 음성 추정치를 생성하는 noisy magnitude response에 적용됩니다.
- Phase-sensitive masking (PSM)은 clean speech와 noisy speech magnitude spectra 사이의 비율이 clean speech와 noisy speech 사이의 phase 위상 차이의 코사인(cosine)을 곱한다는 점을 제외하면 IRM과 유사합니다. 이론적으로 이것은 cIRM의 real 성분만을 사용하는 것과 같습니다.
- Time-domain signal reconstruction (TDR)은 IFFT를 수행하기 위해 subnet을 추가하여 clean time domain siganl을 직접 재구성합니다. 이 IFFT subnet에 대한 입력은 mixture magnitude에 적용되는 T-F 마스킹 subnet의 마지막 hidden layer의 활동 (ratio mask을 재구성)과 noisy phase로 구성됩니다. PSM 및 TDR 추정을 위한 입력 feature과 DNN 구조는 IRM 추정과 일치합니다.
- Complex-domain nonnegative matrix factorization (CMF)는 프로세스에 phase response가 포함된 non-negative matrix factorization (NMF)의 확장입니다. 보다 구체적으로, NMF는 신호를 basis와 활성 행렬로 factor화하며, 여기서 basis 행렬은 스펙트럼 구조를 제공하고 활성 행렬은 주어진 신호를 근사화하기 위해 기준 요소를 선형적으로 결합합니다. 두 행렬 모두 음이 아닌 행렬이어야 합니다. CMF의 경우 basis와 가중치는 음이 아니지만 각 T-F단위를 곱하는 phase 행렬이 생성돼 각 스펙트럼 basis이 mixture에 가장 적합한 phase를 결정할 수 있습니다 [26]. [27]에서 구현한 대로 supervised CMF를 사용하여 음성 분리를 수행하며, 여기서 두 소스 (speech와 noise)에 대한 행렬은 DNN에서 사용되는 동일한 훈련 데이터와 별도로 훈련됩니다. speech와 noise 기준은 각각 100개의 기본 벡터로 모델링되며, 5개의 프레임에 걸쳐 있는 context window으로 보강됩니다.
최종 비교를 위해 서로 다른 magnitude spectrum을 phase spectra와 결합하여 magnitude 또는 phase response를 향상시키는 접근 방식을 평가합니다. phase 추정을 위해 추정된 기본 주파수를 사용하여 voiced speech의 spectrum의 phase를 재구성하여 noisy speech의 phase response를 향상시키는 최신 시스템을 사용합니다 [7]. phase spectrum을 분석하여 시간에 따른 phase 및 주파수 축에 따른 고주파(harmonics)를 개선합니다. 추가적으로 Griffin과 Lim[28]의 표준 phase 강화 방법을 사용하며, magnitude response을 고정하고 phase response만 업데이트하도록 하여 STFT와 역 STFT를 반복적으로 계산합니다. 이러한 접근 방식은 phase response만 향상시키므로 [7]에서와 같이 추정된 IRM으로 separated 음성(RM-K&G 및 RM-G&L로 표시) 및 noisy speech(NSK&G 및 NS-G&L로 표시)의 magnitude response와 결합합니다. 이러한 magnitude spectrum은 추정된 cIRM으로 분리된 음성의 phase response와도 결합되며 각각 IRM-cIRM 및 NS-cIRM으로 표시됩니다.
C. Objective Results
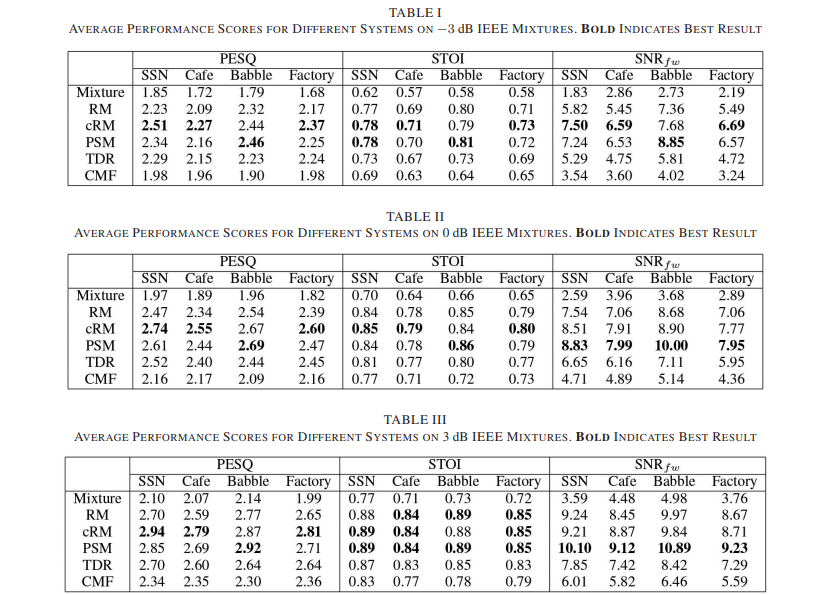
각 접근 방식에서 분리된 음성 신호는 perceptual evaluation of speech quality (PESQ)[29], short-time objective intelligibility (STOI) 점수 [30] 및 frequency-weighted segmental SNR(SNRfw)[31]의 세 가지 객관적 지표로 평가됩니다. PESQ는 분리된 음성과 해당 clean 음성을 비교하여 계산되며, 점수가 높을수록 품질이 우수하다는 것을 나타내는 [-0.5, 4.5] 범위의 점수를 산출한다. STOI는 clean 음성 및 분리된 음성 사이의 짧은 시간 시간적 envelopes의 상관관계를 계산하여 객관적 지능을 측정하여 점수가 높을수록 더 나은 지능을 나타내는 [0, 1] 범위의 점수를 얻는다. SNRfw는 각 시간 프레임과 임계 대역에서 weighted signal-to-noise ratio를 계산한다. PESQ와 SNRfw는 인간 음성 품질 점수와 높은 상관관계가 있는 것으로 나타났으며 [31] STOI는 인간 음성 지능 점수와 높은 상관관계가 있다.
IEEE발화를 사용한 다양한 방법의 객관적 결과는 각각 -3, 0, 3dB의 mixture SNR에서 결과를 보여주는 표1, 2 및 3에 제시되어 있습니다. 굵은 글꼴은 노이즈 유형 내에서 가장 잘 수행된 시스템을 나타냅니다. 표 1부터 시작하여 PESQ측면에서 각 접근 방식은 각 noise에 대해 noisy음성 mixure에 대한 품질 개선을 제공합니다. CMF는 각 noise에 대해 일관되게 수행되지만, noisy speech에 비해 PESQ가 가장 적게 개선됩니다. 추정된 IRM(즉, RM), 추정된 cIRM(즉, cRM), PSM 및 TDR은 각각 noisy speech 및 CMF에 비해 상당히 개선되었으며, cRM은 SSN, Cafe 및 Factory Noise에 대해 가장 잘 수행되었습니다. magnitude의 ratio masking에서 complex domain의 비율 마스킹으로 전환하면 각 noise에 대한 PESQ점수가 향상됩니다. STOI측면에서 각 알고리즘은 noisy speech보다 향상된 점수를 생성하며, 여기서 다시 CMF는 가장 작은 개선을 제공합니다. 추정된 IRM, cIRM 및 PSM의 STOI점수는 거의 동일합니다. SNRfw측면에서 PSM이 가장 높은 점수를 생성하는 bubble noise를 제외하고 추정된 cIRM은 각 노이즈에 대해 가장 잘 수행됩니다.
0dB SNR에서의 성능 추세는 표2와 같이 -3dB에서의 성능과 유사하며, 각 방법은 처리되지 않은 noisy speech보다 객관적인 점수를 개선합니다. 0dB에서 CMF는 mixture에 비해 -3dB에서와 거의 동일한 양의 PESQ 및 STOI개선을 제공합니다. CMF에 대한 STOI점수 또한 가장 낮으며, 이는 NMF기반 접근법이 음성지능을 향상시키지 못하는 경향이 있다는 일반적인 이해와 일치합니다. CMF는 noisy음성보다 SNRfw를 평균 1.5dB개선합니다. IRM대신 cIRM을 예측하면 객관적 품질이 크게 향상됩니다. bubble을 제외한 각 noise에 대한 cIRM의 PESQ점수는 PSM과 TDR보다 좋습니다. 목표 intelligibility 점수는 모든 noise유형에서 RM, cRM 및 PSM에 대해 거의 동일합니다. SNRfw 성능 측면에서 PSM 각 noise유형에서 약간 더 나은 성능을 발휘합니다.
표3은 3dB에서 분리 성능을 표여주는데, 이것은 -3 및 0dB의 경우보다 상대적으로 쉽습니다. 일반적으로 추정된 cIRM은 PESQ측면에서 가장 잘 수행되지만 RM, cRM 및 PSM 사이의 STOI점수는 거의 동일합니다. PSM은 가장 높은 SNRfw점수를 생성합니다. CMF는 noisy speech보다 일관되게 개선되었지만 다른 방법보다 성능이 떨어집니다.
마스킹 기반 방법에 대한 위의 결과는 DNN이 보이지 않은 noise에 대해 훈련 및 테스트 되었지만, 확인된 SNR(즉, -3, 0및 3dB)을 통해 생성됩니다. SNR을 아는 것이 성능에 영향을 미치는지 결정하기 위해, 우리는 또한 훈련 중에 볼 수 없는 SNR(즉, -3 및 6dB)을 사용하여 이러한 시스템을 평가합니다. 표4는 -6 및 6dB에서의 평균 성능을 보여줍니다. SSN, Cafe 및 Factory noise 예상 cIRM에 대한 PESQ결과 는 -6dB 및 6dB로 가장 높고 PSM은 Babble에서 가장 높습니다. STOI결과는 추정된 cIRM, IRM 및 PSM에 대해 거의 동일합니다. PSM은 SNRfw측면에서 가장 잘 작동합니다.
접근 방식을 추가로 분석하기 위해 섹션 4-A에 설명된 대로 TIMIT 말뭉치를 사용하여 각 시스템(CMF 제외)의 PESQ성능을 평가합니다. 각 노이즈에 대한 평균 결과는 표 5에 나와 있습니다. 위의 단일 스피커 사례와 마찬가지로 cRM은 SSN, Cafe 및 Factory noise에 대해 각 접근 방식을 능가하는 반면, PSM은 Babble noise에 가장 적합합니다.
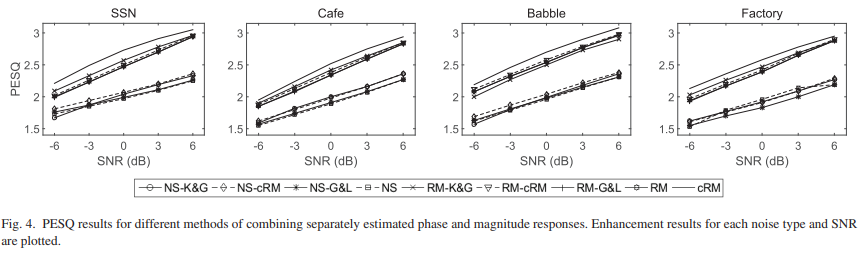
그림 4는 magnitude 및 phase response를 별도로 강화하여 음성을 재구성할 때, PESQ결과를 보여줍니다. 그림은 모든 SNR 및 noise유형에서 각 시스템의 결과를 보여줍니다. magnitude response은 추정된 IRM으로 분리된 noise speech 또는 speech에서 계산되는 반면, phase response은 추정된 cIRM으로 분리된 음성 또는 [7], [28]의 방법에서 계산된다는 점을 기억합시다. 처리되지 않은 noisy speech, 추정된 cIRM 및 추정된 IRM의 결과는 표1에서 4까지 복사되어 각 사례에 대해 보여집니다. noisy magnitude response를 사용하는 경우 (각 그림의 낮은 부분) 서로 다른 phase 추정기 사이의 객관적 품질 결과는 서로 다른 noise유형과 SNR에 근접합니다. 보다 구체적으로 Cafe와 Factory noise의 경우 NS-K&G와 NS-cRM의 결과는 동일하며 NS-G&L의 성능은 약간 떨어집니다. 이러한 추세는 0d를 초과하는 SNR의 SSN에서도 나타납니다. magnitude response가 추정된 IRM에 의해 가려질 때 유사한 결과를 얻으며, 각 phase 추정기는 유사한 PESQ점수를 생성합니다. 또한 이러한 결과는 phase 강화된 신호를 처리되지 않은 noisy speech 및 추정된 IRM으로 구분된 음성과 비교하여 이러한 phase 추정기가 처리되지 않은 IRM 강화 magnitude response에 적용될 때 작은 객관적 음성 품질 개선을 얻는 다는 것을 보여줍니다. 이 비교는 magnitude와 phase response을 별도로 높이는 것이 최적이 아님을 나타냅니다. 반면에 cIRM의 real 성분과 imaginary성분을 공동으로 추정하는 것은 noise 유형 및 SNR조건에 걸친 다른 방법에 비해 PESQ개선으로 이어진다는 것은 결과를 통해 명백합니다.
D. Listening Results
객관적인 결과 외에도 피실험자가 신호 쌍을 비교할 수 있도록 청취 연구를 수행했습니다. IEEE utterances가 이 task에 사용되었습니다. listening study의 첫 번째 부분은 complex ratio masking과 ratio masking, CMF 그리고 magnitude와 phase을 별도로 향상시키는 방법을 비교합니다. listening study의 두 번째 부분에서는 cIRM 추정치를 단계에 민감한 PSM 및 TDR과 비교합니다. 연구 동안 피험자들은 품질 비교에 대한 선호도 평가 접근법을 사용하여 품질 측면에서 선호하는 신호를 선택합니다 [32], [33]. 각 신호 쌍에 대해 참가자는 신호 A가 선호되거나 신호 B가 선호되거나 신호의 품질이 거의 동일한 세 가지 옵션 중 하나를 선택하라는 지시를 받습니다. 청취자는 각 신호를 적어도 한 번은 재생하도록 지시 받습니다. 선호하는 방법에는 +1의 점수가 부여되고, 다른 방법에는 -1의 점수가 부여됩니다. 세 번째 옵션을 선택하면 각 방법에 0점이 부여됩니다. 환자가 처음 두 옵션 중 하나를 선택하며 고품질 신호에 대해 0~4범위의 개선 점수를 제공합니다. 제공 점수 1,2,3 및 4는 선호신호의 품질이 각각 다른 신호보다 약간 더 우수하고, 더 우수하며, 크게 우수함을 나타냅니다 ([33]참조). 또한 신호 중 하나가 선호되는 경우 참가자는 음성 품질, 소음 억제 또는 둘 다 자신의 결정에 도움이 되었음을 나타낼 수 있는 선택 이면의 추론을 나타냅니다.
listening study의 첫 번째 부분의 경우, 신호와 접근 방식은 섹션 3부터 4-B까지 기술된 대로 생성되며, 여기에서 추정된 cIRM, 추정된 IRM, CMF, NS-K&G 및 처리되지 않은 noisy speech가 포함됩니다. 0 및 3dB SNR에서 SSN, Factory 및 Babble noise의 조합으로 처리된 신호가 평가됩니다. 다른 SNR 및 noise 조합은 우리의 목표가 지능이 아닌 perceptual quality 평가이기 때문에 처리된 신호가 청취자가 완전히 이해될 수 있도록 보장하는 데 사용되지 않습니다. 각 과목 테스트는 연습, 훈련 및 형식 평가의 세 단계로 구성되어 있으며, 연습 단계는 대상자에게 신호의 유형을 숙지시키고 훈련 세션은 대상자에게 평가 과정을 숙지시킵니다. 각 단계의 신호는 서로 다릅니다. 공식 평가 단계에서 참가자는 120가지 비교를 수행하며, 여기서 (1) 추정된 cIRM에 대한 noise 음성, (2) NS-K&G로 추정된 cIRM, (3) 추정된 cIRM에 대한 추정된 IRM, (4) CMF 추정된 cIRM에 대한 30가지 비교를 수행합니다. 30개의 비교는 SNR(0 및 3dB) 및 noise(SSN, Factory 및 Babble)의 각 조합의 5개 세트에 해당합니다. 연구에 사용된 발화는 테스트 신호에서 무작위로 선택되며, 쌍의 제시 순서는 각 주제에 대해 무작위로 생성되며, 청취자는 신호를 생성하는 데, 사용되는 알고리즘에 대한 사전 지식이 없습니다. 신호는 개인용 컴퓨터를 사용하여 Sennheiser HD 265 헤드폰을 통해 다이어티컬하게 표시되며 각 신호는 동일한 사운드 레벨을 갖도록 정규화됩니다. 대상은 방음식에 앉습니다. 각자가 정상 청력을 스스로 보고한 23에서 38세 사이의 10명의 피험자(남성 6명과 여성 4명)가 연구에 참여했습니다. 모든 과목들은 영어 원어민이고 그들은 오하이오 주립대학에서 모집되었습니다. 각 참가자는 금전적 인센티브를 받았습니다.
listening study의 첫 번째 부분의 듣기 연구 결과는 그림 5(a)-(c)에 표시되어 있습니다. 선호도 점수는 그림 5(a)에 나타나 있으며, 각 쌍별 비교에 대한 평균 선호도 결과를 보여줍니다. 추정된 cIRM을 noisy speech (즉, NS)과 비교할 때, 사용자는 87%의 비율로 추정된 cIRM을 선호하는 반면 noisy speech는 7.67%의 비율로 선호합니다. 두 신호의 품질은 시간의 5.33%에서 동일합니다. NS-K%G와의 비교는 cIRM, NS-K&G 및 평등선호도 비율이 각각 91%, 4.33%, 4.67%인 경우 유사한 결과를 제공합니다.
가장 중요한 비교는 추정된 cIRM과 IRM사이의 것인데, 이는 complex domain 추정이 유용한지 여부를 나타내기 때문입니다. 이러한 비교를 위하 참가자들은 89%의 비율로 IRM보다 추정된 cIRM를 선호하며, 여기서 추정된 IRM과 평등에 대해 각각 1.67%와 9.33%의 선호도가 선택됩니다. 추정된 cIRM과 CMF를 비교한 결과, 유사한 결과가 나왔으며, 추정된 cIRM, CMF, 동등성은 각각 86%, 9%, 5%의 선택률을 보였습니다. 각 비교에 대한 개선 점수는 그림 5(b)에 나와있습니다. 이 그림은 평균적으로 사용자가 추정된 cIRM이 비교 접근법보다 약 1.75점 더 낫다고 표시한다는 것을 보여줍니다. 즉, 추정된 cIRM이 개선 점수 척도에 따라 더 나은 것으로 간주된다는 것을 의미합니다. 다른 비교에 대한 추론 결과는 그림 5(c)에 나타나 있습니다. 참가자들은 추정된 cIRM을 NS, NS-K&G 및 CMF와 비교할 때, noise suppression이 선택이유임을 나타냅니다. 추정된 cIRM을 추정된 IRM과 비교할 때 사용자들은 음성 품질이 81%의 비율로, noise suppression가 49%의 비율로 선택 이유임을 나타냅니다.
listening study의 두 번째 파트에는 별도의 과목이 모집되었습니다. 정상 청력 자신신고를 한 32~69세 사이 원어민 영어 과목 5개(여성 3개, 남성 2개)가 참여했습니다. 한 피험자도 연구의 첫 번째 부분에 참여했습니다. 평가 중에는 0dB SNR에서 SSN, Factory, Babble 및 Cafe noise의 조합으로 처리된 cIRM, TDR 및 PSM 신호가 사용됩니다. 각 참가자는 40가지 비교를 수행합니다. 여기서 20가지 비교는 cIRM과 TDR신호 간 비교이고, 20가지 비교는 cIRM과 PSM 신호 간 비교입니다. 두 경우 각각 20개의 비교에 대해 4개의 noise 유형 각각에서 5개의 신호가 사용됩니다. 발화는 테스트 신호에서 무작위로 선택되었고 청취자는 신호 생성에 사용된 알고리즘에 대한 사전 지식이 없습니다. 피험자는 cIRM 추정치를 PSM 및 TDR 추정치와 비교할 때, 신호 선호도만 제공합니다.
listening study의 두 번째 파트에 대한 결과는 그림 5(d)와 같습니다. 평균적으로 선호도가 69%인 PSM신호보다 cIRM신호가 선호되는 반면, PSM 신호는 11%의 비율로 선호됩니다. 청취자들은 cIRM 신호과 PSM신호의 품질이 20%의 비율로 동일 하다고 느낍니다. cIRM신호와 TDR신호간 선호율과 동일율은 각각 85%와 4%이며 피험자는 11%의 비율로 cIRM신호보다 TDR 신호를 선호합니다.